Annagram
For my first project in this blog I write from scratch a pointer network with a transformer backbone. For smaller inputs its a silly idea because exhaustive checking would be quick and accurate. That approach though would in a combinatoric fashion. On the other hand a transformer-based encoder/decoder will grow quadratically with input length. Granted there is still optimizations we could use in a deterministic search scheme, but what fun would that be? erif --> fire || sichpys --> physics || nfuctnio --> function
What are pointer nets? Pointer Nets came out several years back, in attempts to setup a simplistic framework for varied length codomains. For a rearrangement problem like anagrams this is sensical approach given that different words have different sizes. These models extend encoder-decoder models, specifically the intial paper uses the seq2seq architecture.
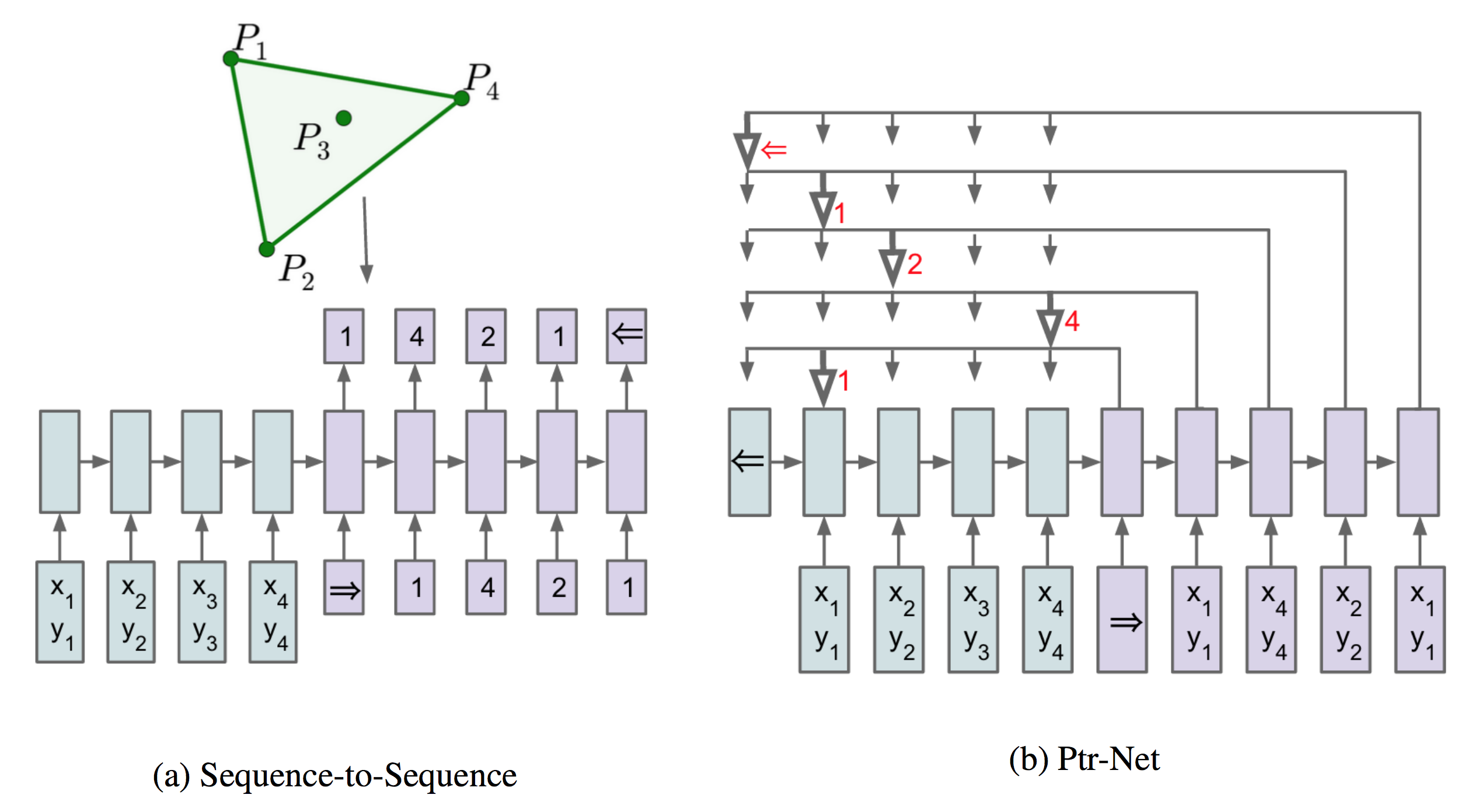
Figure stolen from pointer-net paper
What is a transformer? Lately due to the rise in language models (Ill probably do a project down the line going through those too) people confuse the term transformer for just encoder portion of the original model which originlly was an encoder-decoder architecture. These models work almost solely on attention. The use forms of dot product attention, which just means each logit is an inner product of the key and query. This decision is due to its ability to be constructed as a matrix multiplication which is easily parallelizable and has efficient implemetnations. They use multiple attention heads to be able to learn various query spaces at a certain feature level. Pros: O(1) layers required for intra-layer communication (Note this only holds where the input fits within the receptive field -- this isnt always the case and there exists different tricks in extending this such as transformerXL). Cons: O(n^2) communications per attention head which can get pricey (Note there exist methodologies to use a tree like communication routine to push communication to O(n log n). This construction though comes at a cost of no temporal state. The original paper makes up for this by using a clever trick of adding frequency-varying sinsoids to the input that give the model the capabilities to learn a temporal representation. From an architectural perspective I feel this places alot of strain on the learning process, but empirically showed just as good results as learned embeddings. In most current implementations though you do see that return to learned temporal embeddings.
![]()
Figure stolen from transformer paper
For this problem, were working on a set with no notion of time or order (on the encoder side) so we dont use any type of positional/temporal embedding. I chose this backbone because it thrives in informational communication along nodes. This aspect was particularly attractive from a design perspective because I can image how I would attempt looking for anagrams, and how this architecture can model that. Intuitively I would first check for combinations of letters that are commonly used together, group those and then use the vowels to glue those together until I hit a word that sounds familiar. On a single RTX2080Ti the model converges in nearly 20 minutes and produces somewhat decent results.
Possible extensions for later:
- we can design this to work with keys that can be used multiple times (example:
kntig --> knitting - we can add in spaces to actually learn to make phrases (example:
nrttgiarhee --> the tiger ran)
Click here to see the Repo
