Projects
A mix of side projects, undergraduate REUs, and blog posts
Cubic Step: We Have More Info, Lets Use It!
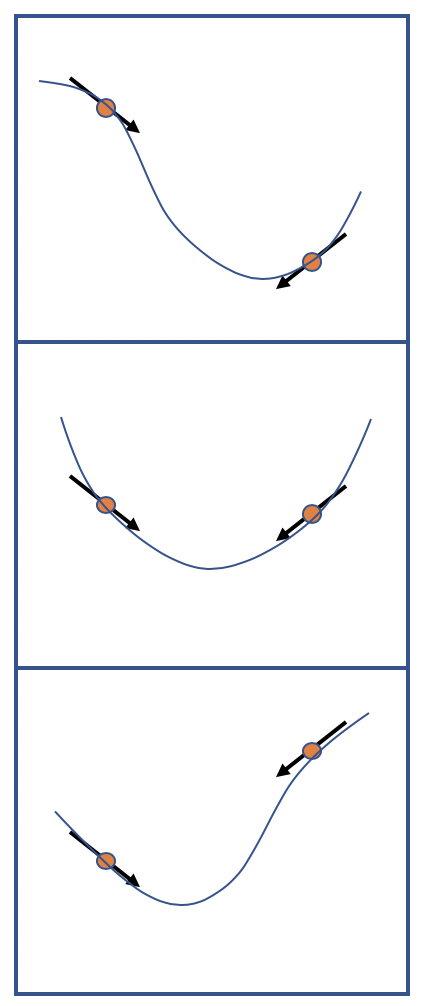
Current gradient based optimization ignores 0th order information. In this post I want to motivate others to try utilizing it
Super-Masks: Are They Good Initializations?
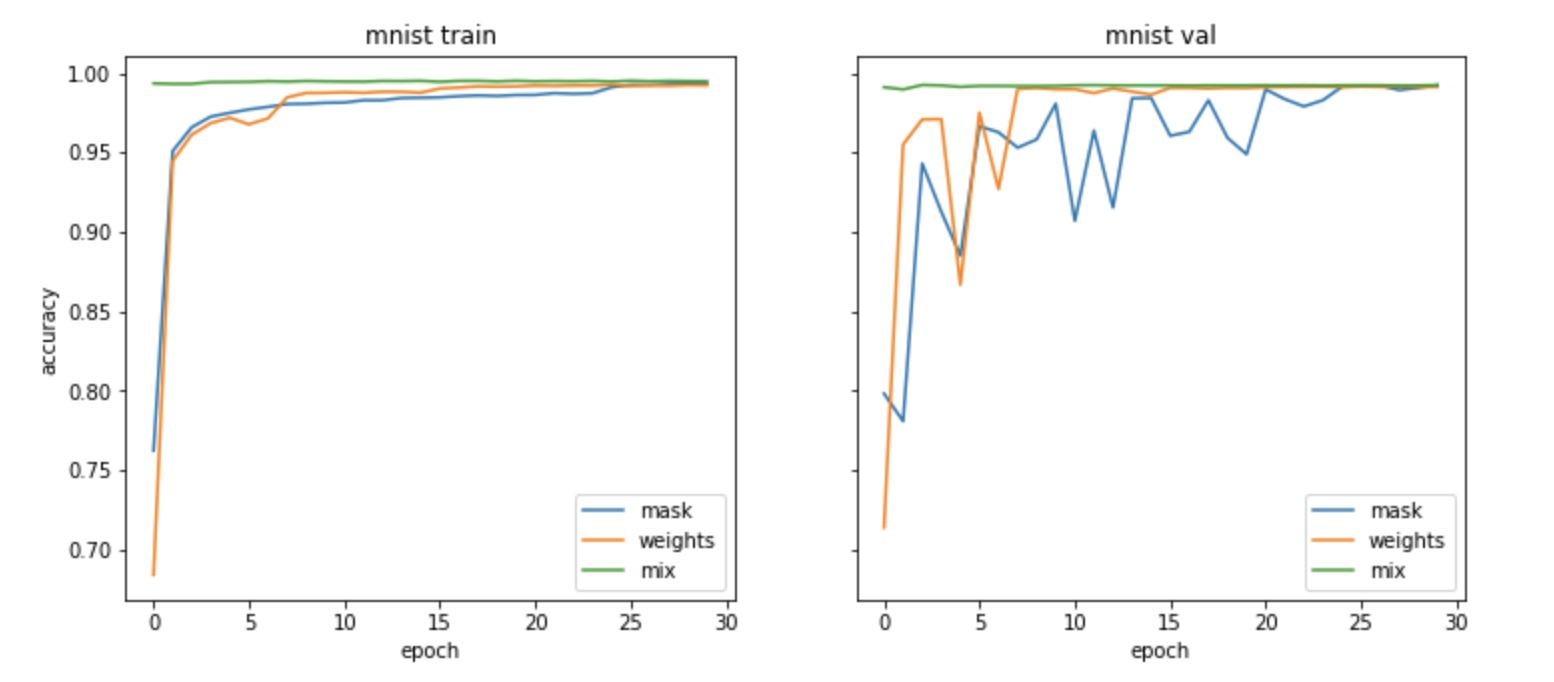
Quick blog post about using Super Masks and how to generate them
Hack Umass Mentor: How to Debug?

I was a mentor at Hack Umass, and this post just describes the fun experience!
Does Focal Loss do what it is supposed to?
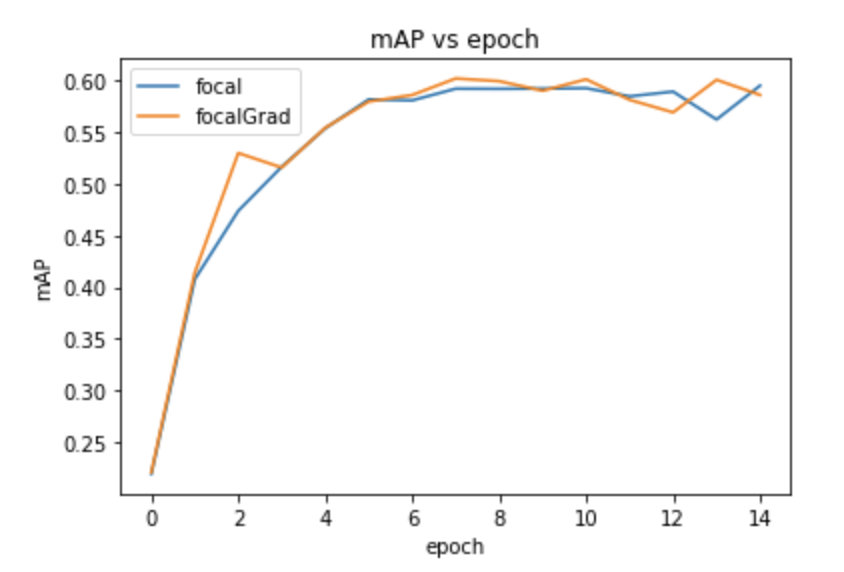
Investigating focal gradient loss' motivation and potential remedy
Intermediate Loss Sampling

An approach to approximate sampling in a differentiablefashion that does not require a distributed representation as in Gumbell Softmax
ANNagram
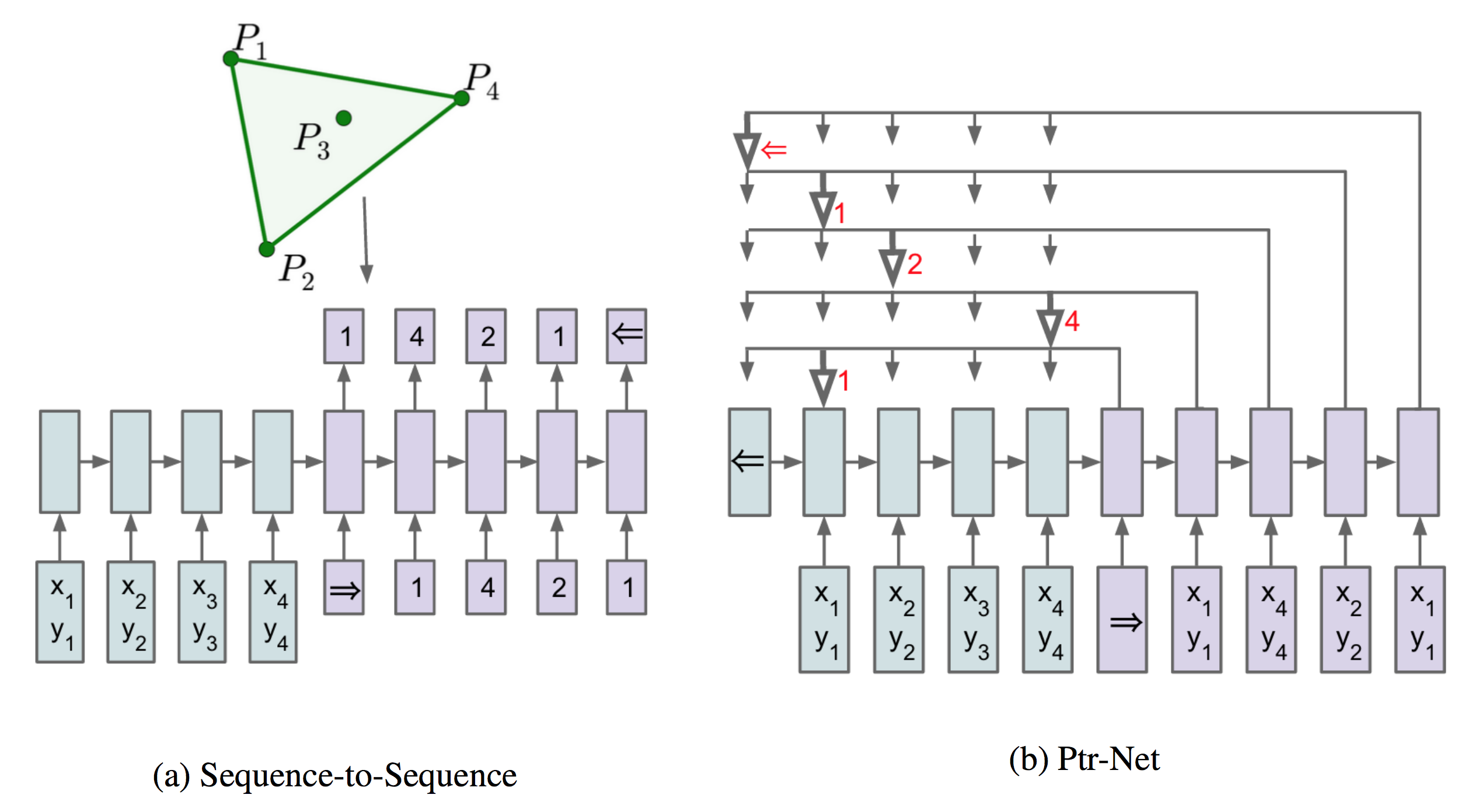
Using Artificial Neural Networks to descramble words
