Intermediate Loss Sampling
I propose a novel sampling approach, leveraging an intermediate loss function to differentiate through a categorical draw. There exists a long history of using policy gradient techniques where only the policy network gradients are utilized, but in the last couple of years approaches like the Gumbel Softmax has surfaced. Gumbel Softmax attempts to model categorical variables through a reparametrization trick and uses softmax to approximate the argmax operator, which in result is completely differentiable. The gumbell softmax is parametrized by a temperature hyperparameter,
Construction
As a forward pass, it is simply the draw itself with no approximations. For a backpass, we define an intermediate loss function

algorithm
### Toy Problems #### Toy Example 1: I show the efficacy of the approach with a toy example where soft-sampling would actually be advantagous. Intermediate Loss Sampling ends up performing just as well if not better. Given a random discrete categorical distribution I solve for minimizing $$\mathbb{E}[KL(\pi_{true} || \pi_{model})]$$ by only having access to singular draws at the time. Given that KL divergence is greater than 0, I show this is a suitable test by showing its an upper bound of our true object and creating a squeeze-based optimization problem.
The simple proof:
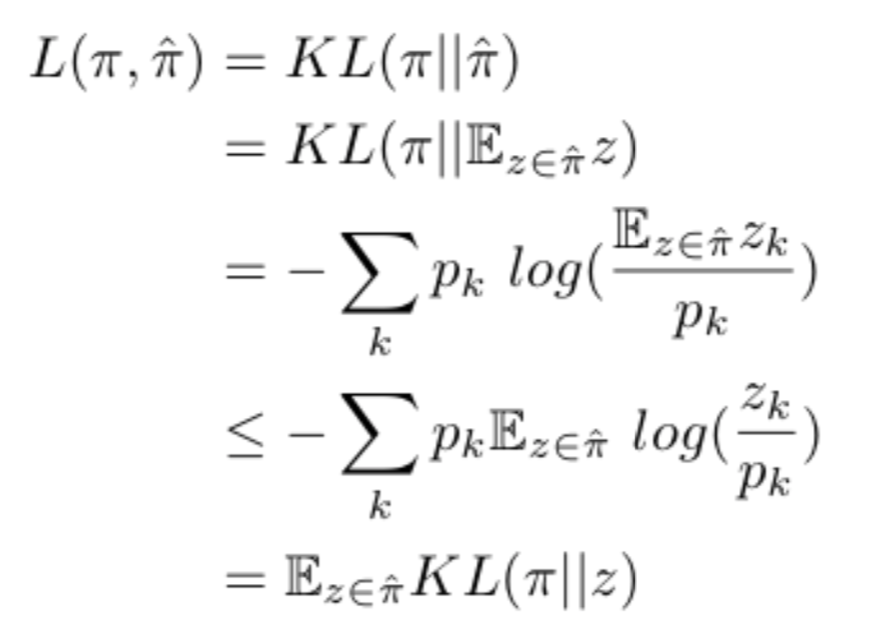
For my experiemnts I use temperatures of .1, 1, 10 for the gumbel softmax and stepsizes of 1e-1, 1e-2, 1e-3 for the intermediate loss sampling.
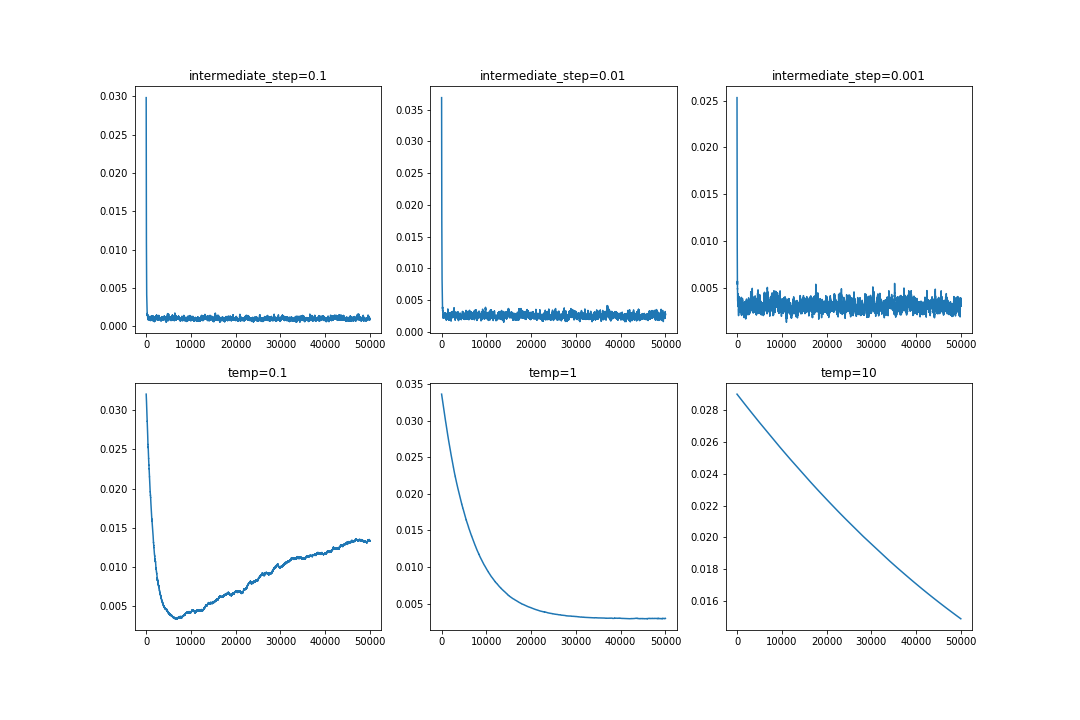
The above shows that in all settings the intermediate loss approach works just as well if not better and converges almost immediately. Note that the noise in the IL settings is because of the inherent variance of using single-step draws, which gumbel-softmax wont have as it can produce smoother outputs than pure one-hot encodings.
I hope to add more test cases soon. Other positives of this method include that it can extend to non-categorical random variables assuming you can find a loss function that is closed-form differentiable with respect to the parameters you are learning.
Click here to see the Repo
