Focal Gradient Loss: Are we looking at focal loss correctly?
Retinanet is a near state-of-the-art object detector that using a simple adaptive weighting scheme, helps bridge some of the gap between one and two stage object detectors by dealing with inherent class imbalance from the large background set constructed by the anchoring process. Specifically they use Focal Loss
FL(p) \propto - (1-p)^\gamma log(p)The usage of
The question I pose with this, is does this accomplish their goal? (I asked this a while back in a stack exchange question). Given the lack of response in that post, I decided to investigate this myself. I propose another simple adaptive weighting scheme, but I propose applying the approach onto the gradient directly. I do this because most optimizers use a form of gradient descent
Comparing the objective functions
Its hard to understand it comparitively with the
Looking at these, we see the focal-loss is a masked version of adaptive weighting plus a residual,
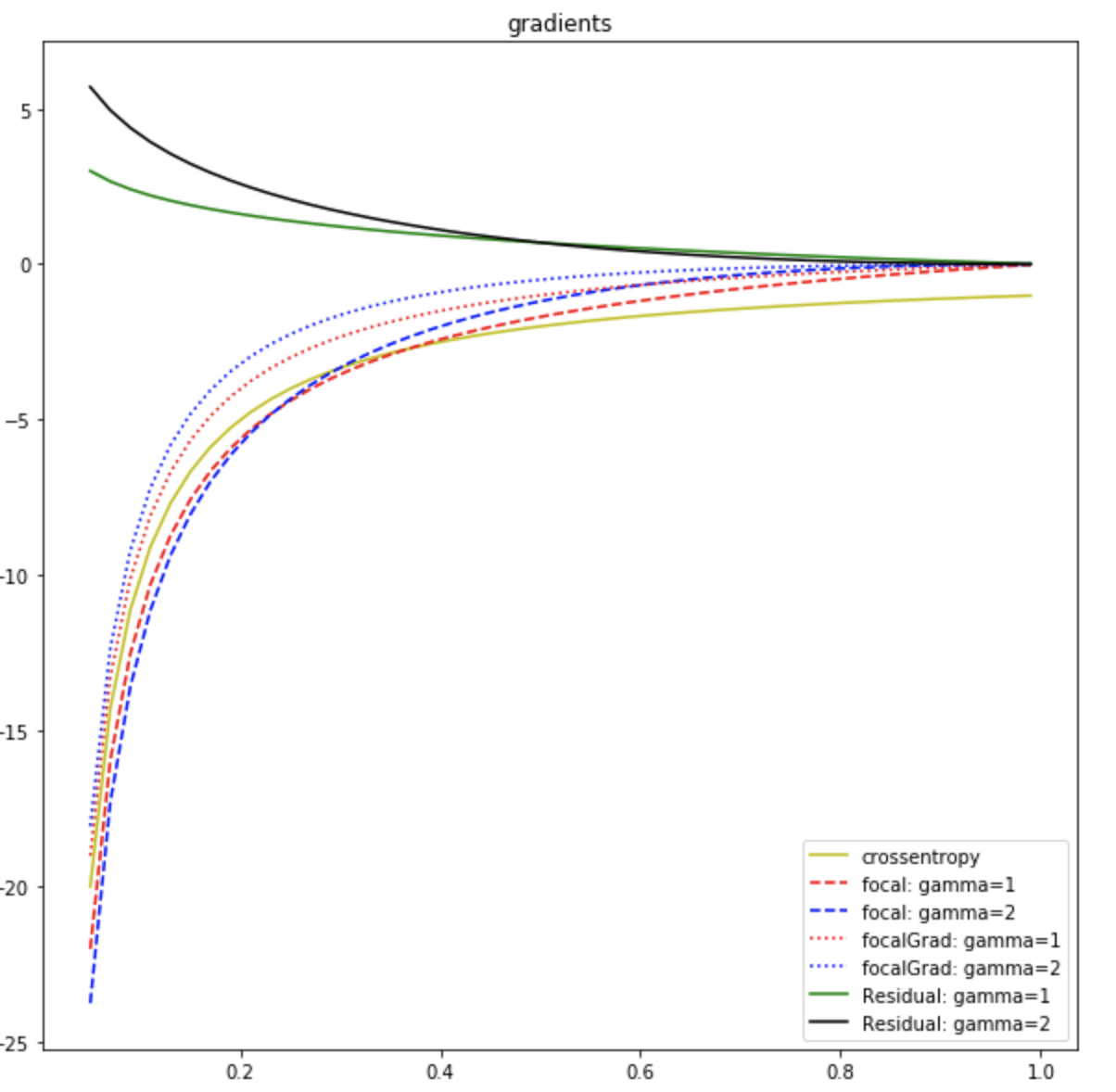
Even though stop_gradient makes it not easily comparable in the loss space, we can integrate its gradient to see its effective equivalent. For values of
Note that the bottom bound of the integral is arbitrary, because it only effects the constant, but since we set
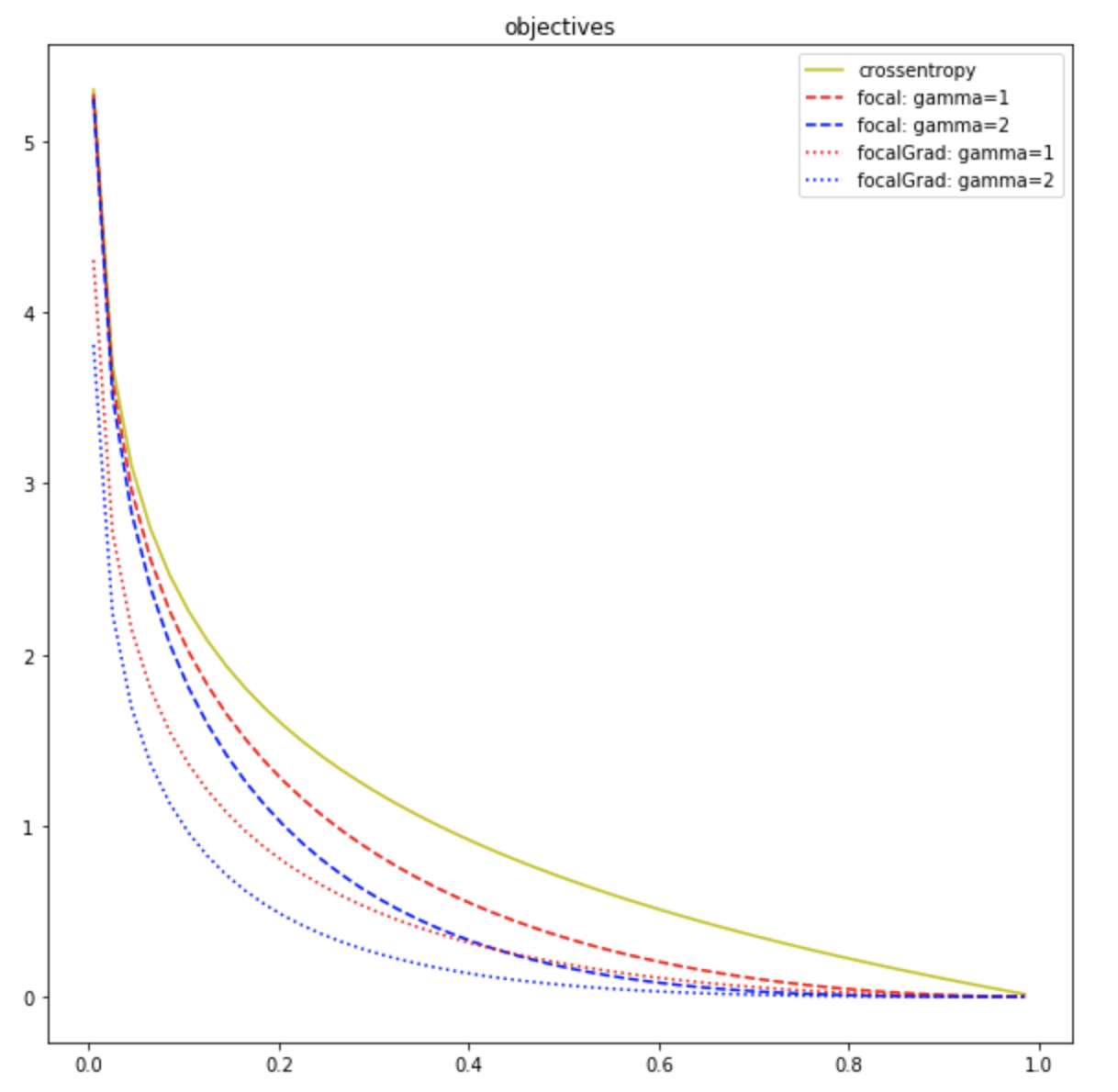
As you can see, focal gradient loss is always lower than the respective focal loss which is understandable based on the spread differential caused by the Residual.
Experiment
Due to computational reasons, we will test on only the setting of
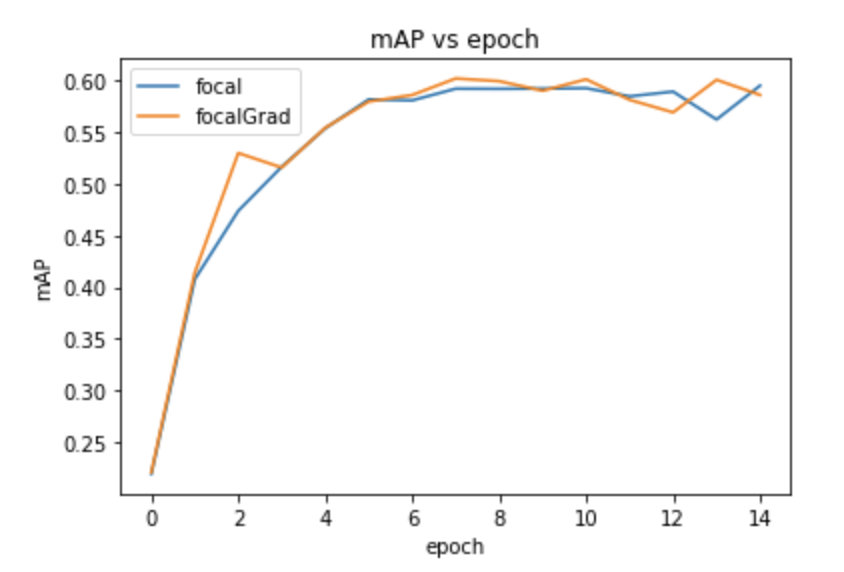
Looking at the results we see they perform similarly. Focal Gradient Loss actually does have a slightly better mAP, but this could be due to noise produced in the training procedure. There is also more noise in general in the Focal Gradient Loss's training compared to Focal Losses-- this may be due to the lack of that additive bias. From this singular (and incomplete) experiment there isnt enough to make conclusions, but if I were forced to do so, I would say the perform similarly but Focal Gradient seems less robust.
I will hopefully be adding more experiments in the future. Stay tuned.
